今天我们来聊一下,如果你/某企业已经有了大数据的硬件平台,那么到底能用它来做什么呢?
http://people.ischool.berkeley.edu/~hal/Papers/2013/BeyondBigDataPaperFINAL.pdf 这篇来自Google首席经济学家的论文对这个问题有简洁明了的阐述:
- 数据的抽取和分析
- 私人化/客户化定制
- 连续不断的实验
- 基于更好的监测而提供新型的服务套餐/合约
直接翻译过来有点拗口,不过具体的例子就很好理解了。今天先说数据的抽取和分析,几乎每个谈到大数据的人都会谈到这一点,这是其最直接而普遍的应用。
比如你提供了一个网络服务,你很想知道这个服务的运行和使用情况,那么怎么办呢?很简单,记Log(日志)就是了:”几点几分,谁,来自哪个IP,访问了哪个服务,成功还是失败”。早些年Log一办就用来监测系统运行是不是正常,通常系统管理员写一些Perl脚步扫描一下就完事儿了。也有人干脆把Log写进数据库,这样用SQL语句就可以查询,非常方便。 题外话:突然想起来之前碰到的一个项目,Log全部记到数据库,后来每天海量的SQL语句插入,查询,终于扛不住了。
后来出现了Hadoop这种的分布式系统,之前做不到的事情可以做了: 公司的老板想知道产品的使用状况;产品经理想知道某个新功能是否受欢迎;市场营销人员想知道到底谁才是目标客户;系统维护人员想知道服务器负载。
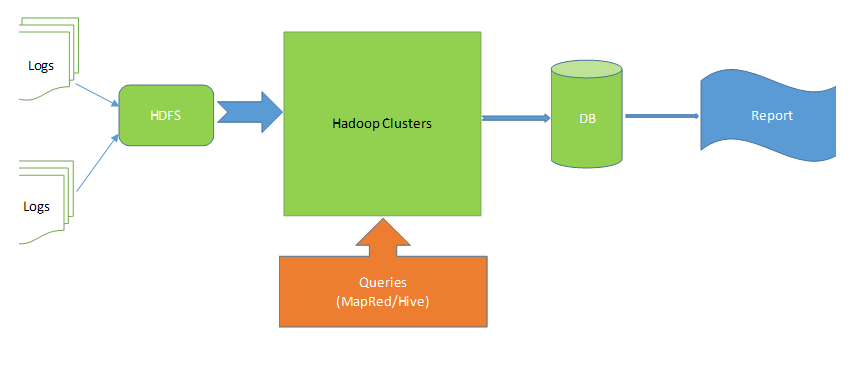
这种系统一般的结构如下:
- 首先把Log集中到HDFS文件系统,然后用Hadoop Cluster访问HDFS。
- 具体的查询语句由用户向Hadoop Cluster提供:用户既可以写MapReduce Job来告诉Hadoop Cluster要怎么处理日志,也可以直接写Hive script. Hive是一种语法很SQL非常像的语言,它首先赋予Log以结构化的定义,然后像SQL语句一样做查询。
- Hadoop运算的结果通常会存储到数据库里。因为运算结果已经是处理过的数据,数据量不大,存储到数据库方便之后快速查询,并且可以和很多现有的基于数据库的应用结合。
- 最后无论是老板的,产品经理的,市场营销人员的,还是系统维护人员的问题,都可以通过从数据库生成的报表来回答。最简单的比如用Excel连接到数据库就可以做报表,复杂的当然有各种各样的报表产品。
在云计算平台逐渐发达的今天,很快就可以搞出这样的系统。即使不用云计算平台,照着文档搭个Hadoop出来,然后部署这样的系统也并非难事。大数据从此不再是什么神秘的,只有少数几家大公司才玩儿的了的事情。
可是如果大数据之做到这个程度,那就太初级了。很多地方在聊大数据,最后无非是在海量数据上计算一个平均值AVG,最大值最小值MAX,MIN;或者按某些东西分分类GroupBy;再或者把两组数据关联一下Join。这几个函数可是初中生就会的。。。所以在大数据很热的今天,机器学习人工智能也很热。一直没有勇气去深入研究一下机器学习人工智能的理论,所有的知识还停留在读书时候读的一点材料。不过我相信只有在大数据集上运用统计学的方法才能得到更多有意思的结果。
现在已经有越来越多的大公司小公司正在把机器学习人工智能的算法搬到cloud上来,我觉得这是个不错的方向。如今这些算法的门槛太高了, 一般的程序员都不太清楚,更谈不上应用了。整个IT产业的历史都是不断把各种技术封装抽象到不同的层次模块,希望机器学习人工智能的最新成果快点被模块化。
发表回复