这两天在折腾这个问题,google中英文的介绍都只提到一部分,所以决定写一篇blog讲一下整个配置过程,全当做笔记。
SSL连接(HTTPS)是普遍使用的安全的HTTP连接方式,它通过证书认证的方式来保证访问安全。通常的方式是:在服务器端设置一张证书,证书由具有公信力的数字证书认证机构(CA)办法给网站对应的域名;用户访问网站的时候浏览器首先会检查证书,既检查证书的合法性(签发机构可靠),也检查证书的对象和网站域名是否匹配(比如证书发给www.foo.com但是用的证书是发给www.bar.com的,那证书很可能是偷来的^^)。如果检查出错,浏览器会询问用户是否继续访问,即使继续访问也会在浏览器地址栏显示一个警告。举个例子,12306购票网站的证书就是它们自己生成的,不是CA颁发的,所以访问12306就会看到

除了认证访问站点的合法性,这张证书还会用来对传输的数据进行加密,这样攻击者就没法通过网络抓包的方式轻易得到用户的账户密码等敏感信息。--虽然12306到证书是自己签的,仍然可以用来加密传输数据。
除了上述服务器端证书认证以外,有时候还会有额外的一步称为客户端证书认证。如果某个站点或某些URL并不希望所有的人访问,可以在建立连接的时候要求客户端也提供证书,只有证书在白名单之列的客户才可以建立连接。这种认证方法在前端并不常用,因为网站给每个注册用户发一张证书很困难,用户保存这张证书也很麻烦。但是在后端比较常用,比如网站的web服务器和后台其他服务器之间进行数据通信的时候。
现在就假设在Apache上运行了一个Django的虚拟站点,这个站点提供一些Rest API,我们只希望拥有证书的客户端能够调用这些Rest API,不对外开放。
设置过程分为以下几步:
1. 生成证书
对于服务器端证书,通常需要从CA去申请,申请的证书和域名是绑定的。如果服务器只是内部使用,并不暴露在Internet下供大家访问,也可以自己生成。客户端证书可以自己生成,并只颁发给信任的客户端使用。因此这里略去向CA申请的过程,只讲怎么自己生成:
a.生成一个host key
$ssh-keygen -f foo.com.key
b.用这个host key创建一个证书申请
$openssl req -new -key foo.com.key -out foo.com.csr
c.由前两步得到的key和证书申请产生一张证书
$openssl x509 -req -days 365 -in foo.com.csr -signkey foo.com.key -out foo.com.crt
二三步也可以合成一个命令
$openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout foo.com.key -out foo.com.key.crt
用同样的方法可以生成另一张客户端证书。如果情况再稍微复杂一点,你有多个客户并且需要一一区分它们,那需要给每个客户单独生成一张证书。这时通常的做法是:先生成一张自己的CA证书(就是自己做自己的权威机构),然后再用这张CA证书分别生成多张不同的客户端证书。关于这一点,我看到一篇很好的reference,可以参考。
2. 在Apache上配置使用SSL
先贴出一个完整的虚拟站点配置文件
<VirtualHost *:443>
ServerName hwind-linux.cloudapp.net
ServerAdmin webmaster@localhost
DocumentRoot /var/www/pyvideo_project
Alias /static /var/www/pyvideo_project/staticfiles
<Directory /var/www/pyvideo_project>
Order allow,deny
Allow from all
</Directory>
WSGIScriptAlias / /var/www/pyvideo_project/pyvideo/wsgi.py
# Available loglevels: trace8, ..., trace1, debug, info, notice, warn,
# error, crit, alert, emerg.
# It is also possible to configure the loglevel for particular
# modules, e.g.
LogLevel debug
#ssl:warn
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
SSLEngine On
SSLCertificateFile /etc/apache2/ssl/crt/hwind-linux.cloudapp.net.crt
SSLCertificateKeyFile /etc/apache2/ssl/key/hwind-linux.cloudapp.net.key
SSLCACertificateFile /etc/apache2/ssl/crt/dev@hwind-linux.cloudapp.net.crt
RequestHeader set SSL_CLIENT_S_DN ""
RequestHeader set SSL_CLIENT_I_DN ""
RequestHeader set SSL_SERVER_S_DN_OU ""
RequestHeader set SSL_CLIENT_VERIFY ""
RequestHeader set SSL_CLIENT_V_START ""
RequestHeader set SSL_CLIENT_V_END ""
RequestHeader set SSL_CLIENT_M_VERSION ""
RequestHeader set SSL_CLIENT_M_SERIAL ""
RequestHeader set SSL_CLIENT_CERT ""
RequestHeader set SSL_CLIENT_VERIFY ""
RequestHeader set SSL_SERVER_M_SERIAL ""
RequestHeader set SSL_SERVER_M_VERSION ""
RequestHeader set SSL_SERVER_I_DN ""
RequestHeader set SSL_SERVER_CERT ""
<Location />
SSLVerifyClient Require
SSLVerifyDepth 1
SSLOptions +StdEnvVars
RequestHeader set SSL_CLIENT_S_DN "%{SSL_CLIENT_S_DN}s"
RequestHeader set SSL_CLIENT_I_DN "%{SSL_CLIENT_I_DN}s"
RequestHeader set SSL_SERVER_S_DN_OU "%{SSL_SERVER_S_DN_OU}s"
RequestHeader set SSL_CLIENT_VERIFY "%{SSL_CLIENT_VERIFY}s"
RequestHeader set SSL_CLIENT_V_START "%{SSL_CLIENT_V_START}s"
RequestHeader set SSL_CLIENT_V_END "%{SSL_CLIENT_V_END}s"
RequestHeader set SSL_CLIENT_M_VERSION "%{SSL_CLIENT_M_VERSION}s"
RequestHeader set SSL_CLIENT_M_SERIAL "%{SSL_CLIENT_M_SERIAL}s"
RequestHeader set SSL_CLIENT_CERT "%{SSL_CLIENT_CERT}s"
RequestHeader set SSL_CLIENT_VERIFY "%{SSL_CLIENT_VERIFY}s"
RequestHeader set SSL_SERVER_M_VERSION "%{SSL_SERVER_M_VERSION}s"
RequestHeader set SSL_SERVER_I_DN "%{SSL_SERVER_I_DN}s"
RequestHeader set SSL_SERVER_CERT "%{SSL_SERVER_CERT}s"
</Location>
</VirtualHost>
a.服务器端SSL
打开服务器端SSL主要由这几行配置指定:
SSLEngine On
SSLCertificateFile /etc/apache2/ssl/crt/hwind-linux.cloudapp.net.crt
SSLCertificateKeyFile /etc/apache2/ssl/key/hwind-linux.cloudapp.net.key
b.客户端SSL
客户端SSL认证主要由这几行配置指定:
SSLVerifyClient Require
SSLVerifyDepth 1
其中SSLVerifyDepth的含义是在证书链中检查的深度。证书是层层签发的,最顶层是CA,因为这里使用的证书都是直接由CA签发,因此是1就可以了。
c.设置Apache把证书信息传给Django应用程序
通常除了在Apache上设置,我们很可能还需要在Django应用程序里根据证书信息做更细致多处理。例如根据证书签名判断访问来自哪个客户,每个客户可能会有不同的权限,看到不同的东西。有两种方案:一个是通过SSLOptions +StdEnvVars的设置把证书信息放进环境变量,再在Apache调用wsgi.py的时候传递过去。这个方案在网上看到有人提到,但是我不知道怎么在wsgi.py中修改request object;如果通过全局变量或者环境变量的方法传递信息,那只能处理单个证书的情形,因为全局变量只能hold一份信息;另一个方案是通过RequestHeader的设置把证书信息加到HTTP request header中去。这个方案经过尝试很好用,示例如下:
在view收到post请求的时候,通过检查存放在request.META中的header信息就可以知道证书是颁发给谁的,之后就可以针对不同的人做不同的响应。
def post(self, request, format=None):
if 'SSL_CLIENT_S_DN_CN' in request.META:
cn = request.META['SSL_CLIENT_S_DN_CN']
3. 浏览器访问
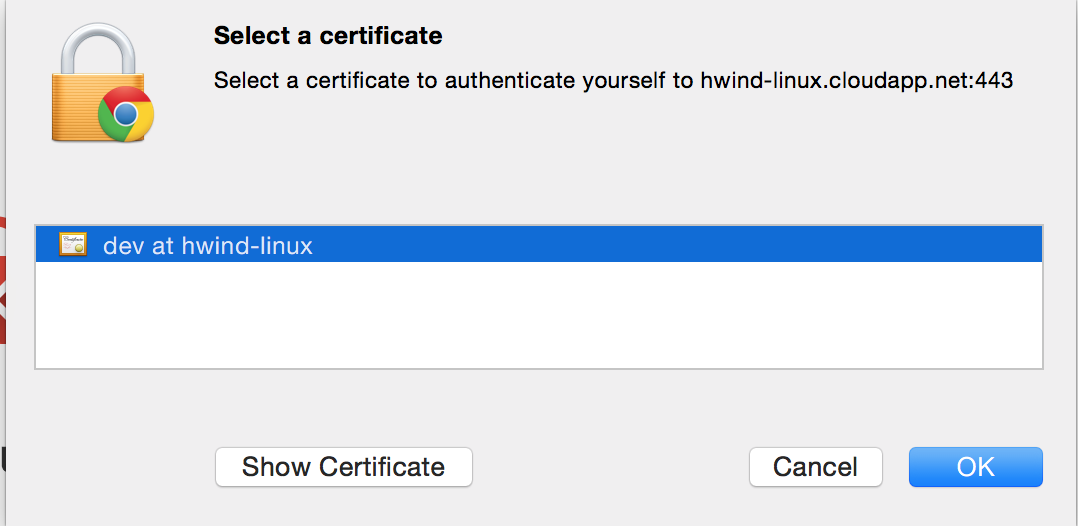
当Apache,Django设置好之后,就可以通过浏览器进行访问了。首先需要在客户端的电脑上安装客户端证书,然后在访问的时候浏览器会弹出窗口,这时选择对应的证书就可以打开网站了。例如,在Chrome中,选择settings-show advanced settings就可以看到
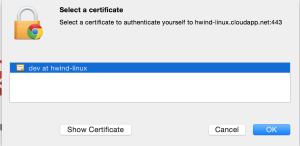
然后在访问的时候选择刚才安装的证书
安装证书的时候需要提供同时包含公钥和私钥的文件,pfx或者p12格式。之前我们提到生成证书的过程生成的是独立的公钥和私钥文件。可以通过以下命令做转换
$openssl pkcs12 -export -out foo.name.pfx -inkey foo.name.key -in foo.name.crt
4.Python访问需要客户端证书认证的Rest API
Python跟http相关的模块比较混乱, urllib2, httplib2, requests, pycurl都可以用来访问RestAPI,但是使用起来的复杂程度各不相同。有兴趣可以参考这篇blog,它对这几个模块访问RestAPI的方式做了详细的比较。总之,结论是requests用起来很方面。
requests天然提供对客户端证书认证的支持,直接这发送请求到时候带上证书的路径作为参数就可以:
def _post(self, url, data):
cert_path = config.get_client_cert_path()
return requests.post(url, verify=False, cert=cert_path, data=data)
上面的cert参数可以是一个指向pem格式证书的字符串,也可以是一个tuple,分别包含cert和key的路径。
requests的一个缺点是它只支持pem格式的证书(不包含密码),但是通常我们得到的都是倒出时包含密码的证书,比如pfx。把pem放在机器里看起来不是很安全。Github上这个open issue也有讨论。
可以通过以下命令把pfx转成pem格式:
$openssl pkcs12 -in foo.com.pfx -out foo.com.pem -nodes
这就是end-to-end全过程,大功告成。