由于我的blog虚拟主机在国外,而且这种共享主机的性能实在差强人意,因此在国内访问blog的速度一直都很慢。另外,因为写游记,大多页面里都包含了不少图片,图片的加载速度成为了整个页面加载速度的瓶颈。最近稍微研究了两种方案来提高图片加载速度:
1. CDN
CDN是Content Delivery/Distribution Network的缩写。简单来说,就是通过一系列分布于全球不同位置的服务器组成的分布式系统来保证网络内容访问的高可靠性(high availability)和高性能(high performance)。比如同样一张图片,复制两份分别放在中国和美国的服务器上,根据访问用户的所在地,有系统自动决定从哪台服务器来做响应。很显然,中国的服务器响应中国用户的速度会快很多,省得比特流跨越太平洋。
CDN适合用于图片,视频,文本这样静态的互联网内容,能够大大提高访问速度。感谢骏骏的帮助,我才知道国内外都有一些CDN的服务提供商,比如http://www.qiniu.com/注册之后就有免费的10G容量,对于个人用户来说足够用了。
使用CDN也很简单:写blog的时候把图片上传到CDN上面,然后把URL贴进文章里边就可以了。别人访问blog的时候,浏览器会自动访问相应的CDN服务器去加载图片。这样图片就能快速加载了。另一方面,图片不从wordpress的虚拟主机里加载,也可以降低虚拟主机的负载。
我最终没有选择这个方案。主要原因是不希望把图片放在另外一个CDN服务商那里,否则我得再花经历去维护这些图片,而放在那里的图片以后迁移备份都可能会有麻烦。另一方面,原来文章里的大量图片需要迁移过去,也不确定迁移的难度有多大,比如很多的URL Link是否需要更新。
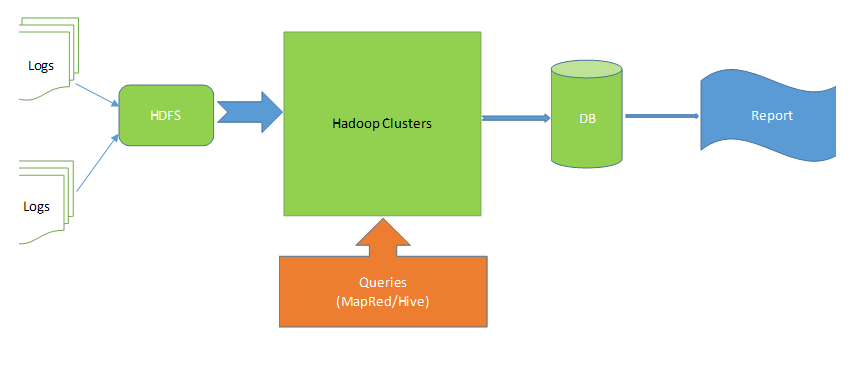
2. 单独host自己的图片服务器
其实这是一个CDN的简化解决方案。我的需求是提高blog页面在国内的加载速度,并不需要有遍布全球的CDN网络,只要有一台位于中国的服务器提供图片访问就足够了。而之所以选择自己host,一方面是因为手头恰好有一台Windows Azure的虚拟机可以利用,另一方面是可以拥有完全的控制权,方便对图片的管理备份,也省得把自己的图片在网络上到处存放。
过程很简单:在Azure VM的IIS 服务器目录下放一个文件夹,把wordpress目录下wp-content/uploads里边的内容用ftp的方式copy过去就可以了,这样所有blog图片的目录结构和新的IIS服务器下是完全一致的。比如http://hwind.me/wp-content/uploads/2014/03/Capture2-300×276.jpg这张图片wp-content/uploads/2014/03/Capture2-300×276.jpg这段路径在两边完全一样。
接下来就是要解决URL重定向的问题。 http://hwind.me会访问到wordpress的虚拟主机,怎样才能让浏览器知道如果后面是访问图片的话,需要去Azure VM的主机上取内容,而不是在wordpress的虚拟主机上呢?Wordpress支持URL Rewrite的方法来实现这个。简单的说,就是可以在根目录下的.htaccess文件里定义一些URL转换的规则,在浏览器真正访问一个URL之前,这个URL的内容会根据这些规则做转换。
为了满足我的需求,只需要加入以下两行config就可以了
RewriteEngine on
RewriteRule ^wp-content/uploads/(.*)$ http://life.hwind.me/blog/wp-content/uploads/$1 [R=301,L]
这个规则就是说,凡是以 wp-content/uploads目录下的资源,都改为去http://life.hwind.me/blog/wp-content/uploads下相同的路径下访问。而http://life.hwind.me就是我Azure VM主机上IIS服务器的地址。这样就实现了重定向。
最终采用了这个方案,所有的文章都不需要做任何更新就可以实现加速访问。有兴趣的人可以自己试一下。
关于费用:CDN服务商提供10G的免费空间,个人使用足够。Azure VM的主机small size一天大约2刀,相比之下也算费用不菲了。当然,一个主机可不仅仅是能做图片服务器这么简单。